I'm excited to share my latest research paper, "Dynamic Temperature Goodness for Enhanced Forward-Forward Learning," introducing a novel approach to improve Geoffrey Hinton's Forward-Forward algorithm for neural network training.
The Challenge of Forward-Forward Learning
In 2022, Turing Award winner Geoffrey Hinton proposed the Forward-Forward (FF) algorithm as a biologically plausible alternative to backpropagation. While innovative, the original algorithm faces significant limitations when applied to complex datasets.
The conventional FF algorithm uses two forward passes (positive and negative) and a fixed "goodness" function based on squared activations. This approach works reasonably well on simple datasets like MNIST but struggles with more complex data like CIFAR-10, where feature distributions vary significantly across layers.
Our Solution: Dynamic Temperature Goodness
After extensive research, I developed DTG-FF (Dynamic Temperature Goodness Forward-Forward), which introduces a principled adaptive mechanism to FF's feature learning process. The key innovation is a dynamic temperature parameter that adjusts discrimination criteria based on feature clarity.
The framework consists of three core components:
Feature Clarity Module: A learnable network that assesses the discriminative quality of features using statistical measures like coefficient of variation and signal-to-noise ratio.
Temperature Control: An adaptive mechanism that lowers temperature for clear features and raises it for ambiguous ones, improving discrimination while maintaining stability.
History Stabilization: A buffer that smooths temperature adjustments based on recent values prevents oscillations.

Theoretical Foundations
Beyond the practical implementation, I've developed a comprehensive theoretical framework that:
Establishes convergence guarantees for the dynamic temperature mechanism
Demonstrates why fixed temperature schemes cannot achieve optimal discrimination
Provides mathematical bounds on feature discrimination capabilities
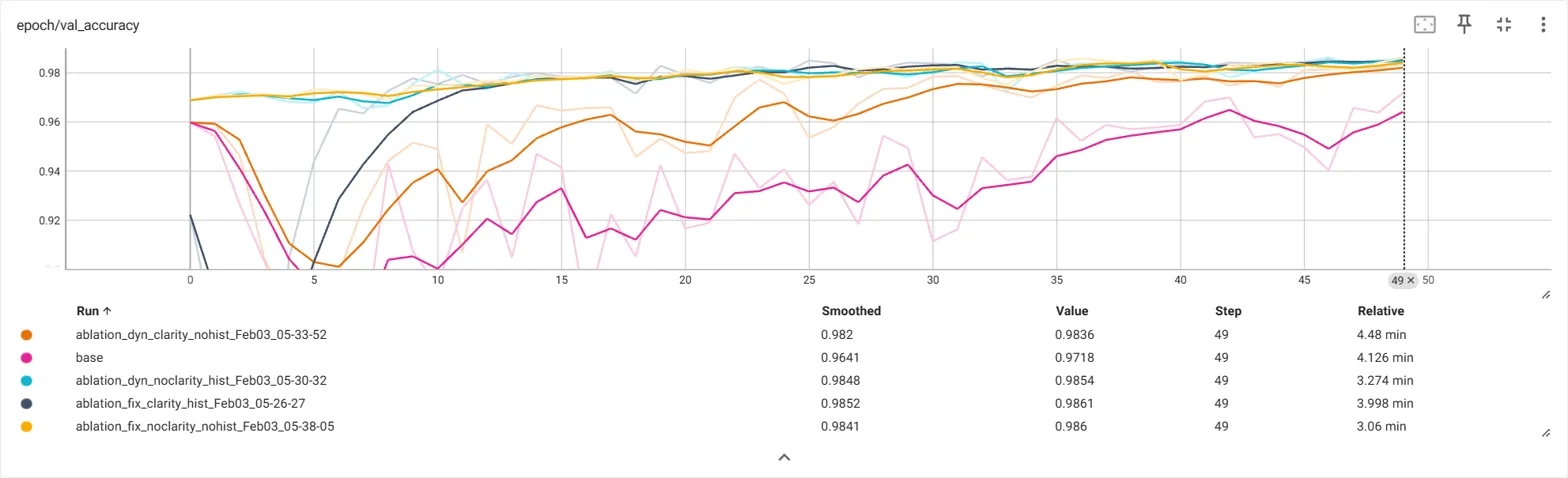
Impressive Results
Our experimental evaluation shows that DTG-FF achieves:
98.9% accuracy on MNIST (maintaining state-of-the-art performance)
60.11% accuracy on CIFAR-10 (an 11.11% improvement over the original FF algorithm)
Significantly reduced computational overhead compared to existing FF implementations
The performance gain on CIFAR-10 represents the largest improvement reported for any FF-based method. This demonstrates that our adaptive approach substantially enhances FF's capabilities without compromising its essential simplicity.
Why This Matters
The success of DTG-FF provides several important insights:
FF's limitations were not inherent to the algorithm itself but to its fixed discrimination criteria
Local feature statistics can effectively guide layer-wise learning in FF networks
The principles of dynamic adaptation and feature-driven optimization appear to be fundamental rather than specific to FF
This research opens up promising directions for extending adaptive discrimination principles to other architectures and learning paradigms, potentially leading to more effective alternatives to backpropagation.
Looking Forward
While our current implementation already shows significant improvements, we're exploring several exciting directions for future work:
More sophisticated feature clarity metrics for complex pattern distributions
Hierarchical temperature adaptation schemes for very deep networks
Extensions to more diverse network architectures and learning scenarios
I believe this work represents an important step toward understanding and improving neural network training beyond traditional backpropagation. The full paper details our approach, theoretical analysis, and extensive experiments.
If you're interested in neural network training methods, biological plausibility in deep learning, or alternatives to backpropagation, I'd love to hear your thoughts on this research!
Appendix


